
Edition 19
Making Your Appium Tests Fast and Reliable, Part 1: Test Flakiness
Let's face it, Appium tests have sometimes been accused of being slow and unreliable. In some ways the accusation is true: there are fundamental speed limits to the automation technologies Appium relies on, and in the world of full-fledged functional testing there are a host of environmental problems which can contribute to test instability. In other ways, the accusation is misplaced, because there are strategies we can use to make sure our tests don't run into common pitfalls.
This article is the first in a multi-part series on test speed and reliability, inspired by a webinar I gave recently on the same subject (you can watch the webinar here). The webinar was so jam-packed with content that I barely had the opportunity to catch my breath in between topics and I still went over time! So in this series we're going to take each piece a little slower and in more detail. For this first part, we'll discuss the blood-pressure-raising notion of test flakiness.
"Flakiness"
No discussion of functional test reliability would be complete without addressing the concept of "flakiness". According to common usage, "flakey" is synonymous with "unreliable"---the test passes some times and fails other times. The blame here is often put on Appium---if a test passes once when run locally, surely any future failures are due to a problem with the automation technology? It's a tempting position to take, especially because it takes us (the test authors) and our apps out of the crosshairs of blame, and allows us to place responsibility on something external that we don't control (scapegoat much?).
In reality, the situation is much more complex. It may indeed be the case that Appium is responsible for unreliable behavior, and regrettably this does happen in reality. But without an investigation that proves this to be the case for your particular test, the problem may with equal probability lie in any number of other areas, for example:
- Unwarranted assumptions made by the test author about app or device speed, app state, screen size, or dynamic content
- App instability (maybe the app itself exhibits erratic behavior, even when used by a human!)
- Lack of compute or memory resources on the machine hosting a simulator/emulator
- The network (sometimes HTTP requests to your backend just fail, due to load or issues outside of your team's control)
- The device itself (as we all know, sometimes real devices just do odd things)
Furthermore, even if it can be proved that none of these areas are problematic, and therefore "Appium" is responsible, what does that mean? Appium is not one monolithic beast, even though to the user of Appium it might look that way. It is in fact a whole stack of technologies, and the erratic behavior could exist at any layer. To illustrate this, have a look at this diagram, showing the various bits of the stack that come into play during an iOS test:
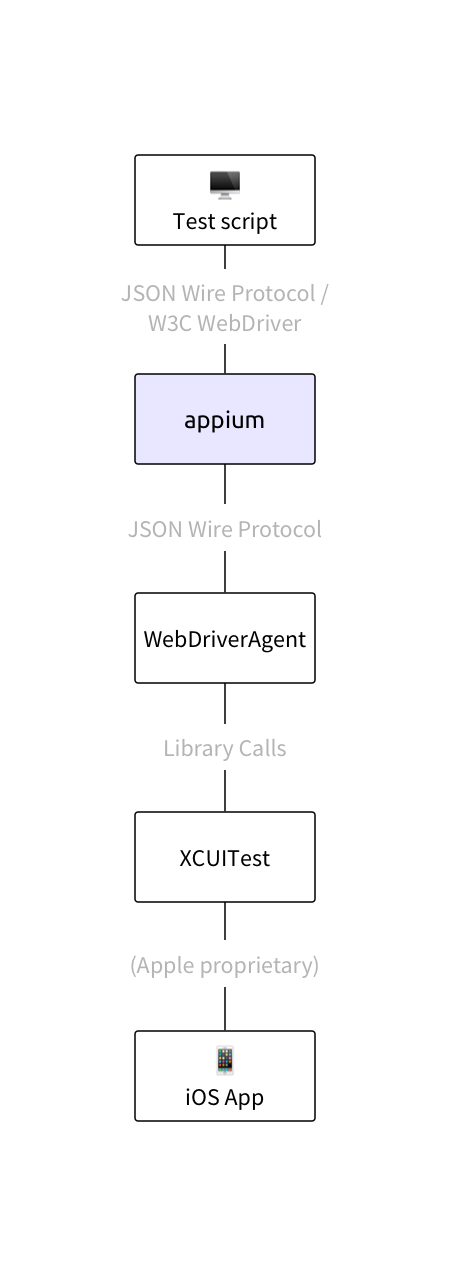
The part of this stack that the Appium team is responsible for is really not that deep. In many cases, the problem lies deeper, potentially with the automation tools provided by the mobile vendors (XCUITest and UiAutomator2 for example), or some other automation library.
Why go into all this explanation? My main point isn't to take the blame away from Appium. I want us to understand that when we say a test is "flakey", what we really mean is "this test sometimes passes and sometimes fails, and I don't know why". Some testers are OK stopping there and allowing the build to be flakey. And it's true that some measure of instability is a fact of life for functional tests. But I want to encourage us not to stick our heads in the sand---the instability we can't do anything about is relatively small compared to the flakiness we often settle for out of an avoidance of a difficult investigation.
My rule of thumb is this: only allow flakey tests whose flakiness is well understood and cannot be addressed. This means, of course, that you may need to get your hands dirty to figure out what exactly is going on, including coming to the Appium team and asking questions when it looks like you've pinned the problem down to something in the automation stack. And it might mean ringing some alarm bells for your app dev team or your backend team, if as a result of your investigation you discover problems in those areas. (One common problem when running many tests in parallel, for example, is that a build-only backend service might be underpowered for the number of requests it receives during testing, leading to random instability all over. The solution here is either to run fewer tests at a time, or better yet, get the backend team to beef up the resources available to the service!)
Like any kind of debugging, investigations into flakey tests can be daunting, and are led as much by intuition as by method. If you keep your eyes open, however, you will probably make the critical observations that move your investigation forward. For example, you might notice that a certain kind of flakiness is not isolated to one test, but rather pops up across the whole build, seemingly randomly. When you examine the logs, you discover that this kind of flakiness always happens at a certain time of day. This is great information to take to another team, who might be able to interpret it for you. "Oh, that's when this really expensive cron job is running on all the machines that host our Android emulators!", for example.
We'll dig into the topic of debugging failed tests in a future part in this series. For now, my concrete recommendation for handling flakiness in a CI environment in general is as follows:
- Determine whether a test is flakey before permanently adding it to your build. In a perfect world, this would look like automatically catching any functional test that's being committed, and running it many times (maybe 100?) to build a reliability profile for it. If it passes 100% of the time, great! Merge that commit to master and off you go.
- If the test doesn't always pass, it's unreliable or flakey. But we can't stop there, because "flakey" is a codeword for ignorance. Time to dig in and find out why it's unreliable. Usually with a little investigation it's possible to see what went wrong, and perhaps adjust an element locator or an explicit wait to handle the problem. At this stage, Appium logs and step-by-step screenshots are essential.
- Once you discover the cause of flakiness, you'll either be able to resolve the flakiness or not. If you can do something to resolve it, it is incumbent on you to do so! So get that test passing 100% of the time. If you determine that there's nothing you can do about it (and no, filing a bug report to Appium or to Apple is not "nothing"), you have two options: either forfeit the test if it's not going to provide more value than headache in the long run, or annotate it such that your CI system will retry the test once or twice before considering it failed. (Or only run it before a release, when you have time to manually verify whether a failure is a "flake").
- If you take the approach of keeping the test in your build and allowing the build to retry it on failure, you must track statistics about how much each test is retried, and have some reliability threshold above which a new investigation is triggered. You don't want tests creeping up in flakiness over time, because that could be a sign of a real problem with your app.
Keep in mind that Appium tests are functional tests, and not unit tests. Unit tests are hermetically sealed off from anything else, whereas functional tests live in the real world, and the real world is much more messy. We should not aim for complete code coverage via functional testing. Start small, by covering critical user flows and getting value out of catching bugs with a few tests. Meanwhile, make sure those few tests are as rock solid as possible. You will learn a lot about your app and your whole environment by hardening even a few tests. Then you'll be able to invest that learning into new tests from the outset, rather than having to fix the same kinds of flakiness over and over again down the road.
Ready for more test robustness? Head on over to Part 2, where we'll talk about quickly and reliably finding elements in your apps!